“Adding peephole optimization to GCC” article covers it for GCC and I decided to cover Clang. Clang is basically a front-end on top of LLVM. It parses C/C++ files into an AST and converts them to an intermediate representation - LLVM IR.
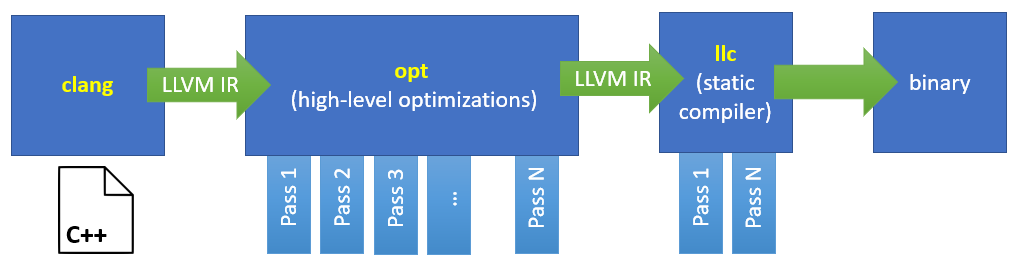
opt is a console application, it accepts LLVM IR and optimizes it using a loop of analysis and transformation phases (produces optimized LLVM IR as an output). Then llc (a console app as well) emits machine code/assembly. opt is basically a PassManager with some generic (actually, C/C++-friendly) order of optimization passes. Other languages or JIT-compilers should use their own order of passes. Thus, when we introduce a new optimization in LLVM we improve many programming languages at once! E.g. Rust, Swift, C, C++, C# (Mono and Burst) - all of them use LLVM as a primary back-end. I assume you’re familiar with some LLVM IR basics such as SSA-form, and If you’re not I highly recommend watching/reading these:
Let’s optimize something!
Although it might sound complicated, some of the compilers’ internals are just quite simple programs you can easily build from sources and improve. For instance, local optimizations (aka peepholes) where you don’t really have to care about surroundings, control flow, etc. I decided to make a step-by-step tutorial on how to create your own optimizations for C/C++. A good source of ideas for peepholes are Math formulas from google/books. I decided to check this one:
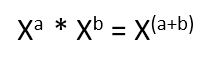
It’s a pretty basic math formula, let’s check if modern C++ compilers handle it well via godbolt (godbolt.org/z/Nvxs4o):
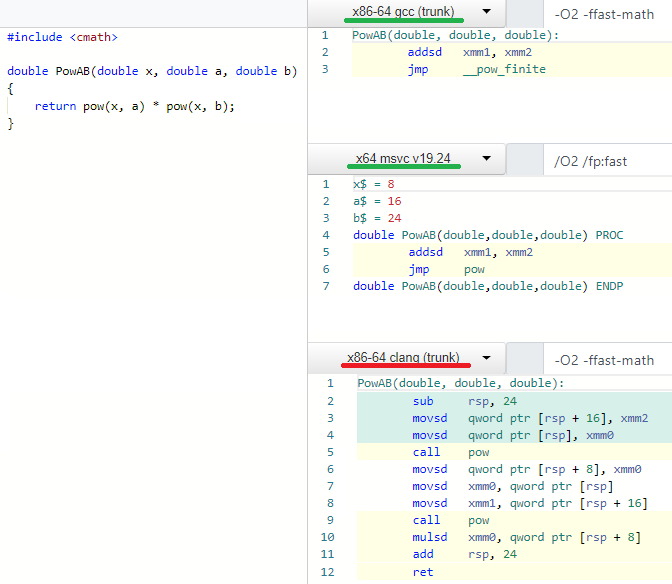
Ouch, so GCC and MSVC managed to recognize it and optimize to pow(x, a+b) but Clang did not. Let’s fix that!
We need to get the LLVM IR clang emits for it first. It can be easily obtained via -emit-llvm argument:
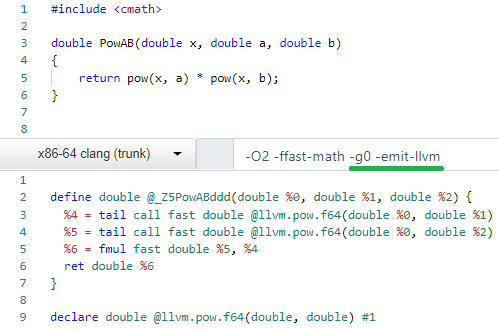
Most of the math.h functions have their built-in LLVM intrinsics. E.g. see my PR for Mono where I
tell LLVM our Math.XY() methods should be LLVM-intrinsics in order to get such optimizations for free.
We, obviously, need somehow transform the IR like this:

See godbolt.org/z/ZGG2dG.
How to build LLVM
LLVM is now hosted at github (moved recently) and uses cmake as a build system so it takes just a few commands to download it and build. We can ask cmake to generate project files for your favorite IDE, for instance VS on Windows and XCode on macOS.
Windows:
1
2
3
4
git clone git@github.com:llvm/llvm-project.git
mkdir myllvm
cd myllvm
cmake -G "Visual Studio 16" ..\llvm-project\llvm
macOS:
1
2
3
4
git clone git@github.com:llvm/llvm-project.git
mkdir myllvm
cd myllvm
cmake -G Xcode ../llvm-project/llvm
Now open LLVM.xcodeproj or LLVM.sln in myllvm folder and build ALL_BUILD target. It might take a while…

Once it’s done we need to prepare a test and it’s simple - just copy that IR from godbolt to a file, e.g. test.ll:
1
2
3
4
5
6
7
8
define double @Test(double %x, double %a, double %b) {
%powa = tail call fast double @llvm.pow.f64(double %x, double %a)
%powb = tail call fast double @llvm.pow.f64(double %x, double %b)
%res = fmul fast double %powb, %powa
ret double %res
}
declare double @llvm.pow.f64(double, double)
I mentioned opt console app several times and actually you can find it in the solution. We are going to use it as an entry-point app
where we pass a path to our test and ask InstCombine to run our peepholes. You need to find that opt project and modify its properties like this:
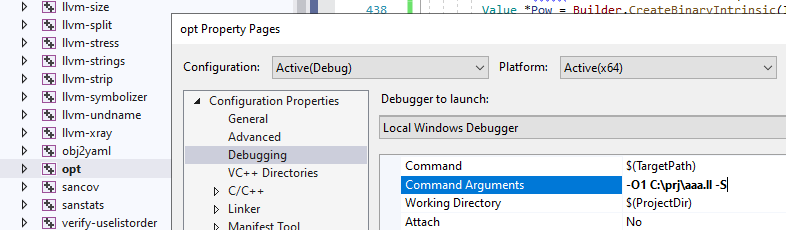
and for XCode (see Edit Scheme):
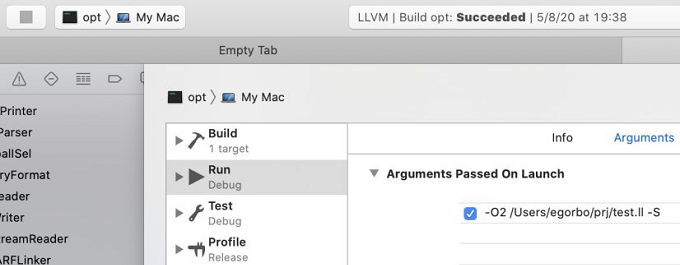
-O1 means run all the optimizations from O1 set (including -instcombine pass). -S means we prefer a human-readable format.
And that’s it! Click “Run/Debug” and you are able to debug LLVM internals: hit breakpoints, view locals!
It’s time to write some code. We want to add a peephole optimization and it means we need InstCombine. Also, we need to optimize
multiplication (FMul, F stands for floating-point) so our entry point is visitFMul in InstCombineMulDivRem.cpp. Let me paste
the optimization there and explain:
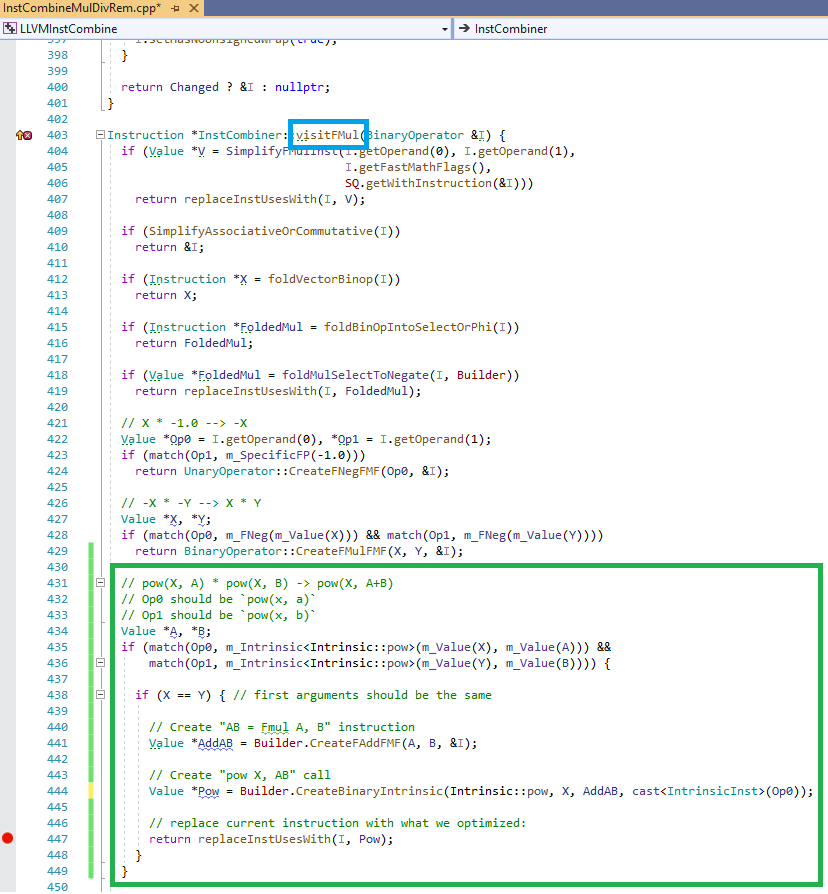
Here we visit a binary node FMul with Op0 and Op1 sub-nodes and we just need to match the pattern we want via match. In our case we want both to be pow intrinsics. It looks super simple and in those InstCombine*.cpp files you can find plenty of similar peephole optimizations. A bit more complicated case is my PR to LLVM: reviews.llvm.org/D79369. Now when we press the Run button we can see the resulting IR:
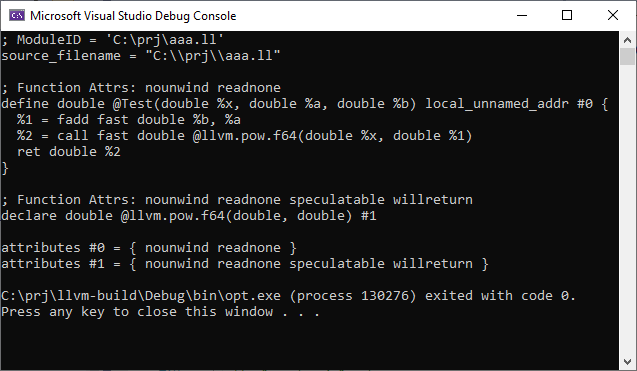
Voila! IR is optimized! Now let me test it for C# (.NET 5.0 Mono-LLVM-JIT)
1
2
3
4
using System;
double PowAb(double x, double a, double b) =>
Math.Pow(x, a) * Math.Pow(x, b);
Codegen (MONO_VERBOSE_METHOD=PowAb):
1
2
3
4
Program_PowAb__double_double_double:
vaddsd %xmm2,%xmm1,%xmm1
movabs $0x7f9f58caeb00,%rax
jmpq *%rax ; pow
It just works! My commit with these changes can be found here (it also handles FDiv and takes care about Fast Math and OneUse checks).
For reference, here is how the optimization is defined in GCC (in a sort of a DSL):
1
2
3
4
/* Simplify pow(x,y) * pow(x,z) -> pow(x,y+z). */
(simplify
(mult (POW:s @0 @1) (POW:s @0 @2))
(POW @0 (plus @1 @2)))
Let me know (e.g. on twitter) if you want me to do the same step-by-step tutorial for RyuJIT and C#.
Links
- “LLVM IR Tutorial (2019 EuroLLVM)”
- “How LLVM Optimizes a Function” by John Regehr
- “Adding peephole optimization to GCC” by Prathamesh Kulkarni