Adding peephole optimization to Clang
“Adding peephole optimization to GCC” article covers it for GCC and I decided to cover Clang. Clang is basically a front-end on top of LLVM. It parses C/C++ files into an AST and converts them to an intermediate representation - LLVM IR.
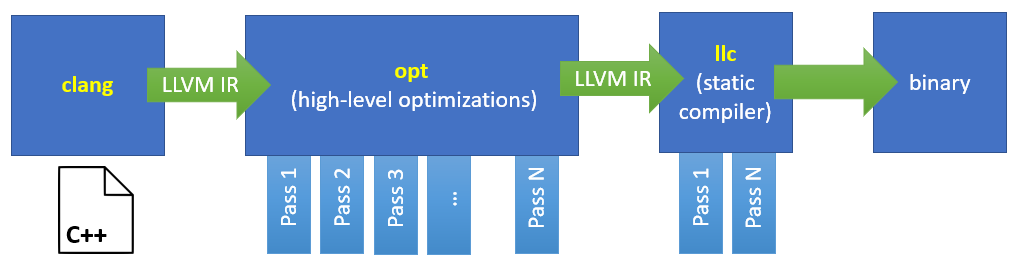
opt is a console application, it accepts LLVM IR and optimizes it using a loop of analysis and transformation phases (produces optimized LLVM IR as an output). Then llc (a console app as well) emits machine code/assembly. opt is basically a PassManager with some generic (actually, C/C++-friendly) order of optimization passes. Other languages or JIT-compilers should use their own order of passes. Thus, when we introduce a new optimization in LLVM we improve many programming languages at once! E.g. Rust, Swift, C, C++, C# (Mono and Burst) - all of them use LLVM as a primary back-end. I assume you’re familiar with some LLVM IR basics such as SSA-form, and If you’re not I highly recommend watching/reading these: